Chapter 2: Introduction
Introduction
In the previous chapter, there is an introduction to the complex scene in which the research has been grounded. It is never easy to know where to start, in complex circumstances, so some preliminary comments were offered in the hope of painting a broad-brush picture into which details could be added as required.
In this chapter, greater detail is offered with respect to the research and the topics under consideration. As the thesis progresses, definitions are enriched but early on there must be some provision for the reader to gain an understanding of the perspectives of the author.
The first decade of international
effort to make the Web accessible has not achieved its
goal and a different, or at least complementary approach is needed. The Web has evolved
significantly in its first decade as has its use. In order
to be more inclusive, the Web needs published resources
to be described to enable their tailoring to the needs
and preferences of individual users. Also, resources need
to be continuously improvable according to a wide range
of needs and preferences. Thus, there is a need for management
of resources and their components. This research asserts
that can be achieved with the correct use of metadata.
The specification of
a metadata framework to achieve such a goal is complex. The requirements are not determined
simply by the end use, but as an environment in which
metadata is specified for an end-use. As the requirements
for that end-use cannot be specified in advance, this is
a meta-design activity. It is transdisciplinary and here,
undertaken in a socio-technical context. The product is
better understanding of metadata, a theoretical contribution
to the field.
This thesis asserts that the low level of accessibility
of the Web justifies a new approach to accessibility and that
the most appropriate is a comprehensive process approach that
brings together a number of strategies for use according to
the circumstances and context. In particular, it should be
possible to continuously improve the accessibility of resources
and for this to be done by third parties, independently of
the original author. This continuous improvement cycle, in
turn, depends on the availability of metadata to manage the
process. Metadata 's role in management is not new but perhaps
is not as well known as its use for discovery.) How that metadata should be developed is at the core of this thesis. The research
responds to the need (documented in Chapter
4) for an effective new approach to accessibility.
The general aim of work in the accessibility field
is to help make the information era inclusive. Inclusive is
a term used in this context to refer to a particular approach
to people with disabilities and to the disabilities themselves.
People with accessibility
needs are not homogenous and many of them do not have long-term
disabilities: what they need now may not be of interest to
them in different circumstances or at other times. Accessibility
is also a special term in this context, designating a relationship
between a human (or machine) and an information resource. Both
terms are defined in Chapter
3.
The Research
The research starts
with a close examination and analysis of current accessibility
processes and tools. It moves on to include a new
approach that will complement previous accessibility work.
Then it addresses the problem of how to develop a metadata
framework to support a more process-oriented approach to accessibility.
Co-editing of international specifications and standards for
accessibility metadata, known as AccessForAll (AfA) metadata,
was undertaken simultaneously with the research to determine
metadata recommendations for several contexts including a Dublin
Core Metadata Application Profile module (see Chapter 7).
Actively promoting
accessibility is taken to mean being inclusive.
The term inclusive is used for operations and organisations
that follow appropriate practices to promote accessibility
and accommodate improvements in a constantly
widening range of contexts. The new process work suggests
a 'quality of practice' approach to the process of content
and service production that will support incremental but continuous
improvement in the accessibility of the Web and thus inclusion
in the digital information era.
Overview of Chapters
The thesis chapters report on:
- the last ten years' efforts to define disability and thus
accessibility (Chapter 3);
- the development of universal accessibility techniques
for making the content of the emerging Web accessible (Chapter
4);
- what success or otherwise has resulted from the universal
accessibility approach and responses to this state (Chapter
5);
- an understanding and definiton of metadata and its potential
role in a networked, digital world (Chapter
6);
- early investigations and efforts in the use and likely
availability of metadata to support accessibility or resources
(Chapter 7);
- a new use of metadata to describe individual user's needs
and preferences with respect to resources in ways that are
useful to people with special needs for effective perception
of their content (Chapter
8);
- a more traditional use of metadata to describe resources
in ways that are useful to people with special needs for
effective perception of the intellectual content of the resource
(Chapter 9);
- an extended use of metadata to manage
digital resource components for matching of compositions
of those resources for individual
users (Chapter 10);
- the definition of interoperability and the need
for technical interoperability of AccessForAll metadata if
its implementation is to become a reality (Chapter
11), and
then
- the conclusion (Chapter 12).
Preliminary, practical definitions
In this section, there are brief introductions to the major
terms and concepts used in the research. These are further
refined in later chapters.
The Web
The United Nations Convention on the Rights of Persons
with Disabilities and its Optional Protocol (UN,
2006) calls for
equity in access to information and communications. In this
thesis, the information and communications of concern are
those that are digital and electronic and the terms are used
both as nouns and as verbs: people need access to hardware
and software to create, store, and deliver digital files as
well as to the intellectual content of the files themselves.
Collectively, these constitute what is called 'the Web' in
this thesis; the Web of digital information and communications.
In particular, the Web is not simply the 'pages' that are
encoded in HyperText Markup Language [HTML
4.01]. While such pages might provide the 'glue', it is
clear that the information and communication enabled by them
is most likely to be made available in a wide range of forms.
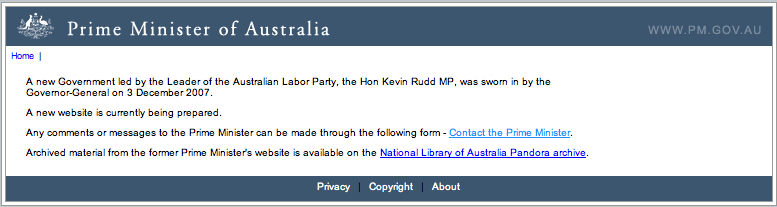
A typical and simple example of an HTML-encoded page is provided
by a temporary 'homepage' of a newly elected
Australian Prime Minister (Figure
5).
On this very small Web page (Figure
5), there are six links that put the user in contact
with other 'pages' as we might call them. To contact the
Prime Minister, one does not send email that would be easily
accessible but, instead, receives another page with a form on it. The
form saves the Prime Minister from receiving email directly
from the user but it also introduces an accessibility issue;
many forms within standard HTML pages are not accessible,
as defined herein.
Links are provided on the Prime Minister's page to three
sources of information that explain privacy, copyright and
about the site. One link directs the user to the archive
of the previous Prime Minister's Web site. This is a substantial
source of information and when contact is made, it reveals
files in a range of formats. This archive is provided by
the National Library of Australia and before choosing a version,
the user can see metadata associated with the archive describing
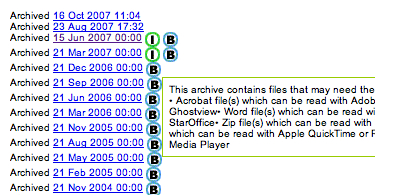
the formats of files involved. (Interestingly (one might say typically), the note does
not always display properly, even on a common
user agent such as Safari (the native browser for Apple Macintosh
computers)
(see Figure
6)).
Only when the 'correct' font size is used is the full note
legible. The so-called ‘correct’ size is that selected by the
resource author, without reference to the user’s needs or preferences.
Figure 7 shows the range of applications necessary to access
what is on the first page of the archive but then, each
page of that archive is likely to point to yet more resources.
All of these resources, the hardware and software needed to
use them, form what in the research is defined to be 'the Web'.
In fact, the Web might include documents to which there is
no Web access, such as paper documents in the National Library,
but they would be included as part of the Web because they
are linked via their metadata. It can also include people, referrred to by URIs.
Web 2.0
In 2004, Tim O'Reilly described the Web using a new term that
has since become a model for describing recent versions of
evolved products that in fact have no formal versions. Later
he said of it (2005):
The concept of "Web 2.0" began with a conference
brainstorming session between O'Reilly and MediaLive International.
Dale Dougherty, web pioneer and O'Reilly VP, noted that far
from having "crashed", the web was more important
than ever, with exciting new applications and sites popping
up with surprising regularity. What's more, the companies
that had survived the collapse seemed to have some things
in common. Could it be that the dot-com collapse marked some
kind of turning point for the web, such that a call to action
such as "Web 2.0" might make sense? We agreed that
it did, and so the Web 2.0 Conference was born.
In the year and a half since, the term "Web 2.0" has
clearly taken hold, with more than 9.5 million citations
in Google. But there's still a huge amount of disagreement
about just what Web 2.0 means, with some people decrying
it as a meaningless marketing buzzword, and others accepting
it as the new conventional wisdom.
The Web has been envisioned by O’Reilly (2005)
as a ‘platform’, an integrated entity:
Like many important concepts, Web 2.0 doesn't have a hard
boundary, but rather, a gravitational core. You can visualize
Web 2.0 as a set of principles and practices that tie together
a veritable solar system of sites that demonstrate some or
all of those principles, at a varying distance from that
core.
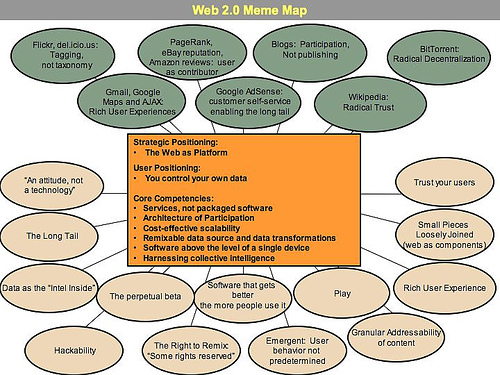
O'Reilly (2005) offered
the following diagram (Figure
8) to help others visualize this 'new' Web.
Figure 8 shows many interactive 'spaces' (grey) as part
of the Web. This means that users do not just receive information
and communications but they initiate or respond to them as
well. For this, they need a range of competencies (orange).
The Web, as it is now, has a number of features (pink).
Web 2.0, the current Web, is vastly different from the world
of paper publications, perhaps most notably in its interactivity
and the fluid nature of the information it contains.
In November 2005, Dan Saffer described Web 2.0 in terms of
the experiences associated with it and with an image (Figure 9):
On the conservative side of this experience continuum, we'll
still have familiar Websites, like blogs, homepages, marketing
and communication sites, the big content providers (in one
form or another), search engines, and so on. These are structured
experiences. Their form and content are determined mainly
by their designers and creators.
In the middle of the continuum, we'll have rich, desktop-like
applications that have migrated to the Web, thanks to Ajax,
Flex, Flash, Laszlo, and whatever else comes along. These
will be traditional desktop applications like word processing,
spreadsheets, and email. But the more interesting will be
Internet-native, those built to take advantage of the strengths
of the Internet: collective actions and data (e.g. Amazon's "People
who bought this also bought..."), social communities
across wide distances (Yahoo Groups), aggregation of many
sources of data, near real-time access to timely data (stock
quotes, news), and easy publishing of content from one to
many (blogs, Flickr).
The experiences here in the middle of the continuum are
semi-structured in that they specify the types of experiences
you can have with them, but users supply the content (such
as it is).
On the far side of the continuum are the unstructured experiences:
a glut of new services, many of which won't have Websites
to visit at all. We'll see loose collections of application
parts, content, and data that don't exist anywhere really,
yet can be located, used, reused, fixed, and remixed.
The content you'll search for and use might reside on an
individual computer, a mobile phone, even traffic sensors
along a remote highway. But you probably won't need to know
where these loose bits live; your tools will know.
These unstructured bits won't be useful without the tools
and the knowledge necessary to make sense of them, sort of
how an HTML file doesn't make much sense without a browser
to view it. Indeed, many of them will be inaccessible or
hidden if you don't have the right tools. (Saffer,
2005)
As Saffer says,
There's been a lot of talk about the technology of Web 2.0,
but only a little about the impact these technologies will
have on user experience. Everyone wants to tell you what
Web 2.0 means, but how will it feel? What will it be like
for users? (Saffer,
2005)
This idea of versions of the Web is clearly abhorrent
to some, as they consider its continuous evolution to be one
of its virtues (Borland,
2007), but the significance of the changes in the Web are
not denied. These comments are made at a time when there is
already talk of Web 3.0. If Web 3.0 represents anything, according
to Borland:
Web 1.0 refers to the first generation of the commercial
Internet, dominated by content that was only marginally interactive.
Web 2.0, characterized by features such as tagging, social
networks, and user- created taxonomies of content called "folksonomies," added
a new layer of interactivity, represented by sites such as
Flickr, Del.icio.us, and Wikipedia.
Analysts, researchers, and pundits have subsequently argued
over what, if anything, would deserve to be called "3.0." Definitions
have ranged from widespread mobile broadband access to a
Web full of on-demand software services. A much-read article
in the New York Times last November clarified the debate,
however. In it, John Markoff defined Web 3.0 as a set of
technologies that offer efficient new ways to help computers
organize and draw conclusions from online data, and that
definition has since dominated discussions at conferences,
on blogs, and among entrepreneurs. (Borland,
2007, page 1)
Kelly (2007) proposes the following, based on ideas from many:
Semantic Web
That internet of things, where everything we make contains
a sliver of connection, is still a ways off, although I believe
we will create it. The internet of data -- the world wide
database -- is quickening right now. As far as I can tell,
this is what people mean by the Semantic Web. Because in
order to be shared, information is extracted from natural
language, reduced to its distinct informational elements,
and tagged into a database. In this foundational form it
can then be re-assembled into meaningful (semantic) informational
molecules in thousands of new ways that is not possible to
do when it remains in a flat un-annotated primitive document.
I believe this shareable extraction of data is also what people
mean by Web 3.0. In this version of the webosphere data surges,
flows, and expands across websites as if it were acting within
one large database, or within one large machine. My site solicits
a steady stream of data from Alice and Bob; it then adds value
by structuring the data in a new (semantic) way, and then I
issue my own streams of organized data, to be consumed by others
as raw data. This ecosystem of data runs on an open transport
system, and consensual protocols, even though not all data
is shared or public.
An operational Semantic Web, or World Wide Database, or
Giant Global Graph, or Web 3.0, will make possible millions
of seemingly smarter services. I won't have to re-tell each
website who my friends are; once will be enough. If my name
shows up in text, it will know it's me. My town will be a
town on the web -- a place with definable characters -- and
not just another word. That ubiquity enables any references
to my town to link to the actual information about the town.
The apparent smarter nature of the web will be due to the
fact that the web will "know" more.
Not in a conscious way, but in a programatic way. Concepts
and items represented on the web will point to each other
and know about each other -- in a fundamental way they do
not right now.
For the purposes of the research, Web 3.0 is defined as a
Web in which not only machines but also humans not just contribute
to established ‘container sites’ in ways anticipated by the
site owners, but they restructure the sites and content and
produce their own sites. This scenario includes a world in
which users fail to recognize or be concerned with the distinction
between their computing environment and the global one. For
this to happen, the users are likely to depend increasingly
on Web-based software and storage that they personalize, but
without necessarily knowing where everything is – just how
to get to it and use it.
The research involves recognising and predicting changes. As
William Gibson wrote, “the future is here, it is just unevenly
distributed” (wikipedia
William Gibson, 2006). It is no longer sufficient to
work on an outdated model that involves merely electronic
publication of traditional materials; the materials have
changed and will continue to do so. As the research shows,
the evolution of the Web offers both new challenges and new
opportunities. Howell (2008)
warns:
We need to keep our eyes on web trends and recognise trends
that actually help to improve disabled people’s experience
of the web. Arguably, personalisation is a trend that actually
helps as its focus is on sites’ best possible performance for
every user and is a great deal more effective that the ‘one
site for all’ approach.
Scope of the Web
The United Nations Convention (2006)
refers to many kinds of digital resources and their location
and use without using the word 'Web' despite the recent revolution
caused by the development of what is known as the Web, or World
Wide Web. Standards Australia, for example, in its
2008 draft metadata standard has included metadata for objects
that are not digital, in the following:
This document
is an entry point for those wishing to implement the AGLS
Metadata Standard for the online description of online or
offline resources. (AGLS, 2008, sec.1.1)
They continue:
The aim of the AGLS Metadata Standard is to ensure
that users searching the Australian information space on
the World Wide Web (including intranets and extranets) have
fast and efficient access to descriptions of many different
resources. AGLS metadata should enable users to locate the
resources they need without having to possess a detailed
knowledge of where the resources are located or who is responsible
for them. (AGLS, 2008, sec.1.5)
Computer operating systems are now being designed with the
user interface driven by metadata in ways that extend the familiar
interface of the 'Web' to personal computers and the files
within them (for example, Sugar on the XO computer (Derndorfer,
2008),
and the Google desktop [Google Desktop].
For this research, the 'Web' is defined as all digitally
addressable resources without necessarily distinguishing between
the applications or formats in which they are developed, stored,
delivered or used by others. This, according to the man credited
with the invention of the World Wide Web, Sir Tim Berners-Lee,
is 'the Web' and as it develops it achieves more diversified
characteristics:
The Semantic Web is an evolving extension of the World Wide
Web in which web content can be expressed not only in natural
language, but also in a format that can be read and used
by software agents, thus permitting them to find, share and
integrate information more easily.[1] It derives from W3C
director Sir Tim Berners-Lee's vision of the Web as a universal
medium for data, information, and knowledge exchange. (wikipedia
Semantic Web, 2007)
The essential feature of the Web, then, is that the resource
can be addressed; that is, it has a Universal Resource Identifier
[URI] that
allows it to be found electronically. Such identifier need
not be persistent (consistent even for dynamically created
content), and the resource need not be maintained in any particular
state; it might be constantly changing and it may not
have continuity.
Brown and Gerrard (2006)
argue that broadband access to Internet makes it easier to
make accessible content. This is in line with other expectations
for the future; as the technology improves, the opportunities
should improve.
Accessibility
It is unlikely that more than 3% of the resources on the Web
are accessible (as defined, see Chapter
3).
In other words, even if a user has appropriate equipment and
has received a resource, the chance that they will be able
to perceive the intellectual content of that resource is extremely
low if they have special needs. It may be that they have a
medically recognised permanent disability such as being blind
and the resource is only available as an image of a poem on
a tombstone. If so, they may have no idea what it is or what
it says. They may have a constructed disability, as a result
of driving a car in a foreign country and using their phone
to try to get location instructions in a language they understand.
The social model of disability (Oliver,
1990b) conflates definitions of disabilities as characteristics
of humans and instead adopts the perspective of the human as
being disabled by the circumstances, natural or constructed,
physical or otherwise (Chapter
3).
(In this thesis, disabilities
of a medical nature are described as permanent
disabilities. It is recognised that some disabilities naturally
increase with age and usually are experienced by all who live
long enough.)
The research concerns the accessibility
of the Web. Accessibility in this context is a match between
a person's perceptual abilities and information or communication
technologies and artefacts. Many people have special needs
to enable this match, especially people with permanent disabilities.
As the UN Convention says:
Persons with disabilities include those who have long-term
physical, mental, intellectual or sensory impairments which
in interaction with various barriers may hinder their full
and effective participation in society on an equal basis
with others. (UN,
2006, Article 1)
The use of
the term accessibility in this research distinguishes
between access as considered in this thesis and access as used
to describe possession of facilities for connection to the
Web. Nor does it include having the necessary legal rights
to use resources. These other kinds of access are, of
course, crucial to any user who is dependent on the Web. Such
access is often dependent upon socio-economic factors, levels
of education, regional and wider factors relating to communications
availability and quality, or any number of similar factors.
It also may be dependent upon such as intellectual property,
state or private censorship, etc. The AccessForAll approach
advocated in this thesis is only concerned with access as it
relates to users who, for whatever reason, cannot access Web
resources, including services, when they are in possession
of facilities that should be adequate; in other words, when
they cannot access what they already have access to.
This is not an exhaustive definition and will be further elaborated
(Chapter 3) but it should
be noted that accessibility in this thesis explicitly includes
people with conditions that are medically recognised as disabilities
and herein described as permanent disabilities.
Metadata
Metadata is the term used, with reference to the Web, to refer
to descriptive labels of content. It is usually applied to
descriptions in an agreed format for the creation of machine-readable
descriptions of digital resources that can be used for, among
other things, the discovery of those resources (wikipedia
metadata, 2008; University
of Queensland Library, 2008;
UK Office for Library
and Information Networking, 2008; W3C
Technology and Society Domain, 2008).
There is a detailed discussion of metadata in Chapter
6.
It explains the multiple
uses of metadata and how it comes to be central in the present
work.
AccessForAll metadata
AccessForAll metadata is, at one level, descriptions
of the accessibility characteristics of resources (note that
metadata is actually a plural noun, although it is easier to
think of it as a singular noun, as is usually done in this
thesis). At another level, it is the way in which such descriptions
are made. It is metadata at the second, latter level that is
the subject of the research. It is described as a metadata
framework to distinguish it from the metadata that is content
produced according to the framework.
The descriptions enable content providers to
create and offer resources that can be adapted to individual
needs and preferences. Thus they can minimise the mismatch
between people who, especially but not exclusively, have special
needs due to permanent disabilities, and resources
published within what is here defined as the Web. This
is explained further in Chapter
7.
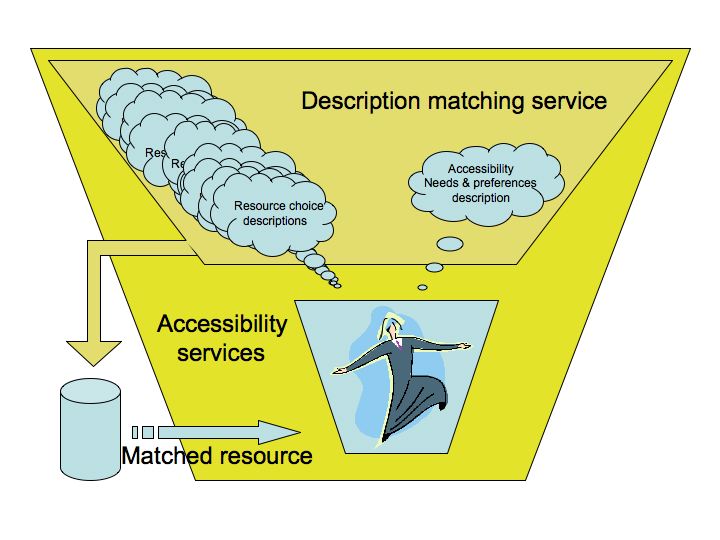
AccessForAll accessibility is based on the use of metadata.
By associating AfA metadata with resources and resource components,
new services are enabled that support just-in-time, as well
as just-in-case, accessibility. Metadata describing individual
people's accessibility needs and preferences is matched with
descriptions of the accessibility characteristics of resources
until the individual user is able to access a resource that
satisfies their needs and preferences (Figure
10).
While nothing can prove that the Web will become more accessible
or otherwise, this research shows that already there are resources
available that could be used to take advantage of AfA metadata,
and make the Web more accessible (Chapter 7). AfA metadata was initially
for education only. It is being further developed as an ISO/IEC
JTC1 multi-part education standard [ISO/IEC 24571]
with some parts already completed. It would be very satisfying if AfA metadata was adopted for resources across all
domains, especially as a result of being adopted by other standards
bodies (already being adopted world-wide by the Dublin Core Metadata Initiative [DCMI] and in Australia as part of the Australia-wide
AGLS Metadata Standard [AGLS]).
Metadata specifications, as explained earlier, can be very
local. As such, they may only work locally, or they can be
shared to form a common vocabulary. Based on earlier similar
work in the library world, metadata specifications do not always
follow technical development practices. In particular, they
are rarely based on a specified model. Practices cannot always
be reduced easily to a technical model because there is often
inconsistency in those practices.
After ten years of practice, the Dublin Core community have at
last managed to state their model explicitly. This has been
a difficult process and has involvd fundamental re-thinking of
many aspects of the practice that have evolved. Now, given
a clear model, all Dublin Core metadata needs to follow that
structure. Often, now, it is simply a matter of adding
semantics to the model. Similarly, the structure of the metadata
for AccessForAll is considered crucial if AccessForAll metadata
is to be effective globally. In this research, the particular metadata elements and their potential values
are not the focus. These are established by the
accessibility community working on AccessForAll, including the
author. They are considered to be data used in the research.
The detailed specifications containing the relevant definitions are being
published (for free) and will be available from various standards
bodies' Web sites [IMS
GLC; ISO/IEC JTC1; AGLS].
The research provides evidence that there is already
metadata available that could be transformed to match an AfA
framework, and that other suitable data could be generated
automatically from existing data (see
Chapter
7).
Currently, such metadata is not available for use by those
with accessibility needs. As a result, individual users cannot
discover, in anticipation of the receipt of resources, if they
will be able to access them. The thesis (Chapter
10) explains how
individual users, possibly assisted by computer systems, could
take advantage of descriptive metadata to meet their accessibility
requirements.
Summary of definitions
In many disciplines,
those working within the narrow discourse of a particular
discipline, or part of it, tend to use words that can have
other or broader meanings in different contexts. The definitions
offered above are not exhaustive but are necessary for the
reading that follows in setting the context for the research.
The research is confined to a small section of information
systems work. It faces the problem that some of the
terms used, such as accessibility, are easily understood in
a general sense by everyone. As such, their particular use
in this context can be confusing. What follows further outlines
the narrow scope of the research and the context and the methods
used in the research.
Research
Scope limitations
A significant problem for people with special needs, and their
content providers, is that there are often intellectual property
issues associated with those resources, especially when they
are transformed for access by users. In many jurisdictions,
there are special rights for people with recognised
disabilities. Their rights may involve complicated intellectual
property rules. This is completely beyond the scope of this
research that focuses on how such
materials can be made discoverable and interoperable, but it
is seen as a potential precursor to any work that needs to
take place to allow such
interaction. (It has been reported informally to the author that
the Copyright Agency of Australia is reviewing its practices
in this respect following interaction with the AccessForAll
work in late 2007).
The research is not about the techniques used to make digital
information accessible to people with disabilities. That
is the work of the World Wide Web Consortium's Web Accessibility Initiative [W3C WAI]. It is recognized as crucial for those
who produce resources because it helps them make content in
suitable ways. Without content that is properly formed, the
metadata framework proposed cannot help. The research is concerned
with how, when a resource is identified
as of interest, a user with particular needs at the time and
in the context in which they find themselves, can have the
intellectual content of that resource presented to them in
a way that matches their immediate needs and preferences. If
necessary, this includes having components of the original
intellectual content replaced or supplemented by the same information
in other modes, or having it transformed. The research contributes
the potential for this to be done, not the components themselves.
A challenging attribute of digital information is the increasing
mobility of people who expect information to be available
everywhere, and expect to use all sorts of devices to
access it. As they travel from one country to another, users
expect to continue to gain information in their language of
choice, even though, for instance, it is about places where
different languages are spoken. Sometimes users expect to get
location-based, or location-dependent, services and sometimes
they want location independent services (Nevile
& Ford, 2004b, Chapter
3).
The context in which a user is operating is fundamental
to the type and range of needs and preferences they will have
(Kelly et al, 2008). The
research embraces what is known as the Web 2.0 and anticipates
Web 3.0. In these Web worlds, an evolutionary progression from
the original Web which was created by the technique of referenced
resources and distributed publishing, users interact with resources
and services that are made available by others, often with
no knowledge of their source. (Discussion of the new environment
and the way it operates is within
scope as it clarifies the context for the work (see
Preamble and Chapter
6).)
It should be noted
that the W3C WAI work currently considers some Web content
out of scope at this stage, in their accessibility
work (W3C WCAG 2.0,
2008).
If a resource contains some components
that are inaccessible to a user, those
components need to be transformed or replaced or supplemented
for the user. It is outside the scope of the current research
to deal with the problem of discovery of those components
or the services that might be used for their transformation.
The problem is considered not so much as peculiar to
accessibility but as a problem related to modified on-going
searching when resources that are discovered prove inadequate.
This has been considered recently at the University
of Tsukuba, in Japan (Morozumi et al, 2006). It is a
topic of research closely related to new work on what are called
GLIMIRS (sic) from the Online
Computer Library Center [OCLC]
in the US (Weibel,
2008a). Understanding of the problem of iterative searching
is, however, in scope.
Out of scope also is any requirement to engage with the details
of adoption of AfA by industry. Adoption by standards bodies
depends upon processes that engage the industry in formal ways,
so adoption by such bodies is considered to include adoption
by industry. Implementation is, on the other hand, not always
ensured by the existence of standards. At the time of writing,
before publication of the standards, there are already some
significant implementations of the AfA standards. These are
discussed in Chapter
11.
Research Methodology
A significant aim of the research is the distillation, from
a perspective developed from working extensively in the fields
of accessibility and metadata, of work undertaken in the
accessibility context on what is called the AccessForAll
approach to accessibility.
Background
Information science is a well-established field. It brings
together computer science and information management, forming
a theoretical field for research into information management.
The Journal of Information Science describes its field thus
(2008):
Information Science is a broad based discipline which has
a potential impact in almost every sphere of human activity
in the emerging information age.
There have been significant advances in information technology
and information processing techniques over recent years and
the pace of innovation shows no sign of slowing. However, the
application of these technologies is often sub-optimal because
theoretical understanding lags behind.
The Journal seeks to achieve a better understanding of the
principles that underpin the effective creation, organization,
storage, communication and utilization of information and knowledge
resources. It seeks to understand how policy and practice in
the area can be built on sound theoretical or heuristic foundations
to achieve a greater impact on the world economy.
Elsevier (2008) says of their journal, Information Sciences:
The journal is designed to serve researchers, developers,
managers, strategic planners, graduate students and others
interested in state-of-the art research activities in information,
knowledge engineering and intelligent systems. Readers are
assumed to have a common interest in information science,
but with diverse backgrounds in fields such as engineering,
mathematics, statistics, physics, computer science, cell
biology, molecular biology, management science, cognitive
science, neurobiology, behavioural sciences and biochemistry.
In his essay Information Science, Tefko Saracevic (1999)
wrote:
In approaching the discussion of information science, I
am taking the problem point of view as elaborated by Popper
(1989, p. 67) who argued that:
[S]ubject matter or kind of things do not, I hold, constitute
a basis for distinguishing disciplines. . . .We are not students
of some subject matter, but students of problems. Any problem
may cut right across the border of any subject matter or
discipline. (Emphasis in the original)
My emphasis is on problems addressed by information science.
Although I provide definitions of information science and
other fields in interdisciplinary relations with information
science later in the essay, I am doing this solely to advance
the understanding of problems addressed by different fields
and their relation to information science problems. Debates
over the “proper” definition of information science, as of
any field, are fruitless, and in expectations naive. Information
science, as a science and as a profession, is defined by the
problems it has addressed and the methods it has used for
their solutions over time. Any advances in information science
depend on whether the field is indeed progressing in relation
to problems addressed and methods used. Any “fixing,” if in
order, will have to be approached by redefining or refocusing
either the problems addressed, or the methods for their solutions,
or both. (1999,
p 1051)
He continues:
A history of any field is a history of a few powerful ideas.
I suggest that information science has three such powerful
ideas, so far. These ideas deal with processing of information
in a radically different way than was done previously or
elsewhere. The first and the original idea, emerging in 1950s,
is information retrieval, providing for processing of information
based on formal logic. The second, emerging shortly thereafter,
is relevance, directly orienting and associating the process
with human information needs and assessments. The third,
derived from elsewhere some two decades later, is interaction,
enabling direct exchanges and feedback between systems and
people engaged in IR processes. So far, no powerful ideas
have emerged about information, as the underlying phenomenon,
or “literature” (as defined later), as the object of processing.
However, one can argue that the idea of mapping of “literature,”
that started with exploitation of citation indexes in 1960s,
may also qualify as a powerful idea. (1999,
p 1052)
He argues there are two major clusters of work in the field
– one around the texts themselves and the other to do with
their management, retrieval, storage, etc. He says:
More specifically, information science is a field of professional
practice and scientific inquiry addressing the problem of
effective communication of knowledge records— “literature”—among
humans in the context of social, organizational, and individual
need for and use of information. (1999,
p 1055)
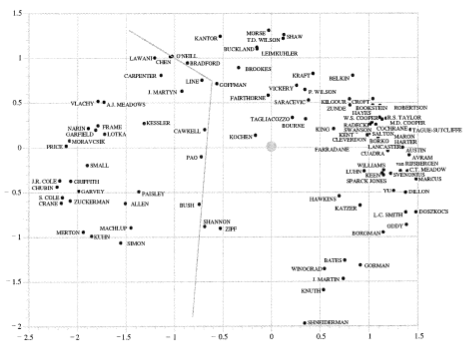
White and McCain (1998)
did extensive data-gathering about the top authors
in the field of information science. The placement of names
in the map below (Figure 11) represents the connections between
the authors. The clusters are, according to Saracevic, on the
left around the analytical study of literatures and those on
the right more around what has become known as information
retrieval. Saracevic notes that the authors are sparsely spread
around what he likens to the coastal areas of Australia, signifying
little connections with whatever is a core of the field. He
notes the sparceness of pure research around literature, as
he calls it. He asserts that there is more money for applied
research, research with respect to information retrieval, and
this partly explains the distribution of authors.
Today, it is safe to guess, one of the ‘coastal towns’ would
be occupied by authors writing about metadata. There is a proliferation
of journals and conferences in the field, and for all the practitioners,
there are many who theorise in universities and research institutes.
Saracevic argues that information science is suffering from
being fragmented and that, at the same time, it engages in
interdisciplinary work. By this, he means that information
science does not operate in a vacuum but rather that it works
with many disciplinary fields. He concludes by saying:
I am also convinced that the greatest payoff for information
science will come if and when it successfully integrates systems
and user research and applications. Society needs such a science
and such a profession. (p
1062)
The International Journal of Metadata, Semantics and Ontologies
(IJMSO,
2008)
describes its objective as follows:
to provide an open forum in which several disciplines converge
and provide their perspectives regarding the complex topic
of metadata creation, use and assessment. Those disciplines
include Digital Libraries, the Semantic Web, Library Science
and Knowledge Management, among others.
There is also the Journal of Library Metadata
The journal with the unique focus on metadata applications
in libraries. (Beall,
2008)
and a steady flow of new books.
Following arguments such as those presented by Saracevic,
based on extensive research of the literature regarding the
field of information science, it is to be assumed there is
no doubt about its status as a science, and that its strength
partly lies in its ability to work collaboratively with other
disciplines. A decade later, it is now asserted, there is a
branch of information science that has earned the name metadata
science, or, at least, that the information science specialty
in which the author is engaged, is a metadata cluster.
In 2003, Jane Hunter summarized the key issues and some of
the research in the metadata field.
She wrote:
Some of the major disadvantages of metadata are cost, unreliability,
subjectivity, lack of authentication, and lack of interoperability
with respect to syntax, semantics, vocabularies, languages,
and underlying models. (2003, page 1)
Hunter (2003,
page 5) distinguishes between metadata research and the development
of what she calls ‘upper-level’ ontologies. In the current
research, such a distinction is drawn by the split between
the work of the AccessForAll team on what Hunter calls the
upper-level ontologies, and the work in this research, to
do with how to make those ontologies work. The AccessForAll
ontologies are contained in the standards, as published,
and so are not considered a core part of this thesis.
Similarly, Hunter distinguishes Web services and harvesting.
A number of such areas of research are relevant but not the
focus of this research. The matching process for AccessForAll,
for example, might be considered a Web Service. Here, it is
simply considered to exist as a ‘black box’ for which the metadata
work is being undertaken. It is not the focus of the work of
the research, although its use is a major motivator for the
AccessForAll development.
Hunter, citing Clifford Lynch (2001) continues:
The individualization of information, based on users' needs,
abilities, prior learning, interests, context, etc., is a major
metadata-related research issue ... The ability
to push relevant, dynamically generated information to the
user, based on user preferences, may be implemented
• either by explicit user input of their preferences;
• or learned by the system by tracking usage patterns and
preferences and adapting the system and interfaces accordingly.
(2003, page 13)
She wrote:
The idea is that users can get what they want without having
to ask. The technologies involved in recommender systems
are information filtering, collaborated filtering, user profiling,
machine learning, case-based retrieval, data mining, and
similarity-based retrieval. User preferences typically include
information such as the user's name, age, prior learning,
learning style, topics of interest, language, subscriptions,
device capabilities, media choice, rights broker, payment
information, etc. Manually entering this information will
produce better results than system-generated preferences,
but it is time consuming and expensive. More advanced systems
in the future will use automatic machine-learning techniques
to determine users' interests and preferences dynamically
rather than depending on user input. (2003, page 14)
For the reasons made clear in this thesis, this is not the
way that the accessibility community wants to work, well, not
exclusively, It is true that some of the capabilities of the
user’s devices should be conveyed automatically to the computer
applications involved, but it is essential that there is control
left in the user to choose what they want. In this sense, the
AccessForAll work is both more than usually dependent on an
appropriate enabling technology, such as metadata, and novel,
in how it does not simply follow the trend. It is also the
case that the AfA work depends much more on a close connection
between the technology and very personal needs and practices,
the human-interface issues that Saracevic (1999,
page 1052) argued are the central
and big problems of information science.
Hunter (2003, page 18) concludes :
The resource requirements and intellectual and technical
issues associated with metadata development, management, and
exploitation are far from trivial, and we are still a long
way from MetaUtopia….
The current research is wholly to do with the intellectual
and technical issues that have arisen from the exercise of
developing AccessForAll metadata. The research methodology
for this has been tailored to that task.
Research strategies
Determining issues is never easy. There is inevitably a perspective
bias from any written interpretation of data. In the research,
the obvious bias is the Dublin Core metadata perspective. This
research has been undertaken within a wider context of extensive
and broad Dublin Core metadata activities over more than a
decade (Appendix ???). Here, the bias is embraced not avoided:
Dublin Core metadata is arguable the most prolific and it is
the recommended metadata in the Australian context [AGLS]. Since the
early days of metadata in the context of the Web, and the use
of the Web for publishing by them, the Australian governments
and their cultural institutions have supported the use and
development of Dublin Core metadata. The research
has challenged aspects of Dublin Core metadata without fear
or favour, and in some cases contributed to its clarification
through the research (Pulis & Nevile, 2006). The bias is, then, not blind
in favour of the Dublin Core work but certainly towards Semantic
Web technologies as fundamental to the potential of metadata,
and thus Dublin Core metadata as the most appropriate expression
of metadata for the Semantic Web. There is an explicit
effort to make DC metadata Semantic Web interoperable, and
this has been of interest since the early days when the PICS
protocol was first being used and the Semantic Web was developed
as an extension of that. (Lassila, 1997)
The research is multifaceted and so involves a number of strategies. The aim is
to use the different strategis appropriately to inform the writing of an integrated theory
of the metadata that can support the AccessForAll approach
to accessibility. The demands of that approach have been used
as drivers for the problem-solving that Saracevic (1999, p. 1051), by implication,
suggests will define the science of metadata.
The research does not include any surveys or quantitative
data, or analysis of original data, although it references
extensively work that does this, and provides some critical
interpretation of those works. It is theoretical work that
attempts to make sense of what can and should be done to achieve
a set of goals. The goals are examined in detail because they
need to be deeply understood for the work to be done. As argued
above, this is not repetitive work. It is not about building
an ontology for accessibility but about how such an ontology
should be built, and why. The building of the actual ontology
is critical grist for that mill. The details of the work are
referred to time and again to show exactly how they should
be understood and responded to.
Pioneering research (Seely Brown, 1998) is about research
that builds something new, a new technology, that cannot be
tested other than by time. This is not such research although
it shares some characteristics.
John Seely Brown (1998) differentiated between what he thought
of as two main kinds of research, sustaining and pioneering.
Sustaining research, he thought, is aimed at analysis and evaluation
of existing conditions. The problem for researchers in fast-changing
fields is that often, by the time sustaining research is reported,
the circumstances have changed. As the original circumstances
cannot be reproduced, the research results need to be interpreted
into a different context to be useful and in some fields, this
cannot happen. In the case of pioneering research, the work
is successfully implemented or, perhaps more often, forgotten.
This is the sort of work in which many technology focused researchers
are engaged: they follow what are traditional research practices
to a point, but their work is evaluated differently and they
need to engage with and accept different types of evaluation.
It is not possible to test today if the AccessForAll metadata
will make a difference. At best, it can be estimated what potential
it has for doing this, and this should be done in an informed
way. But the research is not about a product that has to be
successful, it is about how to make such a product, what are
the relevant factors. Similarly, it is not about what has been
done in the past when a metadata project has been successful,
although that is relevant. There are lessons from the past
that are taken to inform the work, but this is a new type of
metadata for a new purpose in a new technological context.
It is not, therefore, the purpose of the research to determine
what has made a particular metadata development successful
although the factors that have done this in a number of cases
should be identified and articulated and their contribution
evaluated. This has been done.
What has been happening is that, in the context of working
on accessibility and ontology development, the principles and
practices of the field have been exposed and they have been
identified, analysed, and evaluated. This has happened in the
light of extensive reading of the literature and relevant practical
experiences. The ‘field’, in this case, has been at the junction
of the fields of accessibility and metadata research.
In the field of accessibility, almost all effort has focused
on a single set of guidelines [WCAG-1] with what this thesis
argues are less than satisfactory results. It is important
to evaluate AccessForAll accessibility to ensure this does
not happen again. For whatever interest there is in the idea
of AccessForAll metadata, there is still a need for research
to discover how to create a suitable awareness of the context
for the work and the value of the work. This means developing
a strong understanding of the theoretical and practical issues
related to accessibility, including practical considerations
to do with professional development of resource developers
and system developers, and the administrative processes and
people that usually determine what these developers will be
funded to do. It also involves the reading and writing of critical
reviews of other work. In particular, while there is little
doubt of the potential benefit to users with disabilities,
it is not at all clear how to work with the prototyped AfA
ideas to make them mainstream in the wider world, both in the
world outside the educational domain and in the world of mixed
metadata schemas (correct use of this word would be schemata
but common usage accepts schemas).
Many use the expression 'research and development' to differentiate
between research and development. Development work is so characterised
without regard for the processes involved in achieving it.
One is reminded of Mitchel Resnick's story of Alexandra whose
project to build a marble-machine was rejected as not scientific
until the process was carefully examined and she was awarded
a first prize for the best science project (Resnick, 2006).
In some fields, development is not about something that can
be controlled over time. It is about repeatedly designing,
creating, testing, evaluating and reviewing something in an
iterative process, often towards an unknown result but according
to a set of goals. These are also important processes for research.
Such processes benefit from rigorous scrutiny that can be attracted
in a variety of ways, including by being undertaken in a context
where there are strong stakeholders with highly motivated interests
to protect.
Designers of educational computer environments, such as Andrea
diSessa,
research in a field they call ‘design
science’ (diSessa, 1991). The ‘experiments’ carried out by
such researchers were first designated ‘design experiments’
by Allan Collins (1992).
They are used to support the design of environments, or what
Fischer calls meta-design. (Fischer &
Giaccardi, 2006)
Ann Brown (1992)
describes the problem of undertaking research in a dynamic
classroom. As an accomplished experimental
researcher, she argues that it is not possible or appropriate
to undertake experimental research in a changing classroom.
Collins later wrote (1998):
Historically, some of the best minds in the world have addressed
themselves to education; for example, Plato, Rousseau, Dewey,
Bruner, and Illich. But they addressed education essentially
as theorists, even when they tried to design schools or curricula
to implement their ideas. Today, some of the best minds in
the world are addressing themselves to education as experimentalists.
Their goal is to compare different designs to see what affects
what. Technology provides us with powerful tools to try out
different designs so that, instead of theories of education,
we can begin to develop a science of education. However, it
cannot be an analytic science, such as physics or psychology,
but rather a design science, such as aeronautics or artificial
intelligence. For example, in aeronautics the goal is to elucidate
how different designs contribute to lift, drag, and maneuverability.
Similarly, a design science of education must determine how
different designs of learning environments contribute to learning,
cooperation, and motivation.
Collins says, “in aeronautics the goal is to elucidate how
different designs contribute to lift, drag, and maneuverability”.
The equivalent in the current context might be: "to elucidate
how different designs contribute to proliferation, interoperability,
effectiveness and user experiences". The particulars in focus
in this research are the effectiveness and interoperability
as there is not yet enough of the AfA metadata to determine
how it will affect user experience and the proliferation cannot
be pre-determined.
In "Design-based research: An emerging paradigm for educational
inquiry",
The authors argue that design-based research, which blends
empirical educational research with the theory-driven design
of learning environments, is an important methodology for understanding
how, when, and why educational innovations work in practice.
Design-based researchers’ innovations embody specific theoretical
claims about teaching and learning, and help us understand
the relationships among educational theory, designed artifact,
and practice. Design is central in efforts to foster learning,
create usable knowledge, and advance theories of learning and
teaching in complex settings. Design-based research also may
contribute to the growth of human capacity for subsequent educational
reform. (DBRC and D.-B. R. Collective, 2003)
The complexity of the accessibility work is like that
of education: everything is constantly changing, including
the technology, the skills and practices of developers; the
jurisdictional contexts in which accessibility is involved
and the laws governing it within those contexts, and the political
environment in which people are making decisions about how
to implement, or otherwise, accessibility. There are also a
number of players, all of whom have different agendas, priorities
and constraints, despite their declaration of a shared interest
in increasing the accessibility of the Web for all.
The main idea behind design-based research is that in the
process of design, one makes explicit the issues that are relevant,
and their context, so these can be dealt with by the researcher.
The actual design is of something that can be thought of as
the motivation for the activity, but is not the product of
the research. The research is design-based, not design. The
design informs the research.
The Australian Research Council funded the Clever Recordkeeping
Metadata (CRKM) Linkage Project in 2003-2005 (ARC,
2007). It
was a major metadata research project for Australia and so
the research methods used are of interest. The project reported:
The first iteration of the CRKM Project investigated a simple
solution for demonstrating the automated capture and re-use
of recordkeeping metadata. The expectation was that this initial
investigation would expose the complex network of issues to
be addressed in order to achieve metadata interoperability
and automate the movement of recordkeeping metadata between
systems, along with enabling researchers to develop skills
and understandings of the existing technologies that support
metadata translation and transformation. (CRKM,
2007)
The project demonstrated the use of an established computer
systems development methodology in the metadata context.
In this case, what the researchers did might be described
by some as follow a computer systems development methodology,
but by others as design-based research. In this case, the
Australian Research Council (ARC) did not fund the development for
the value of the development, per se, but because the process
of development would inform the research. The current research
is in a similar position. In 2002, the author was the principal
Investigator in a major ARC project that, at that time, broke
all the ARC rules by funding development (ARC, 2001). The ARC
accepted the argument that only by doing the development, could
the lessons be learned that were essential to the research.
In the introduction to a paper describing the research
methodology for the CMKM project, Evans & Rouche (2006)
claim:
Systems development research methods allow exploration
of the interface between theory and practice, including their
interplay with technology. Not only do such methods serve
to advance archival practice, but they also serve to validate
the theoretical concepts under investigation, challenge their
assumptions, expose their limitations, and produce refinements
in the light of new insights arising from the study of their
implementation. (p.
315)
Engagement with the development of AccessForAll metadata
enabled accessibility research that "needs to encompass
methods that investigate how emerging theories are operationalized
through systems development". In the case of the CRKM
project, the researchers were interested in discovering how
schemas played a role in the archival context so they would
know how to build a metadata registry that uses such schemas
(p.
316). In the current accessibility research, the focus
is on how to develop metadata schemas for use in content discovery, matching and delivery systems, to improve the accessibility
potential of the Web.
The CRKM registry was to provide content for use in a harmonisation
of schemas to inform a standardisation process. In the words
of the researchers:
The purpose of such a registry of metadata schemas is to
act as a data collection and analysis tool to support comparative
studies of the descriptive schemas.
With no existing blueprint for such a registry, the
first task of the research team was to conceptualise the
system and establish its requirements. In so doing several
key questions are raised including: – What are the salient
features of metadata schemas that need to be documented for
the purposes outlined above? How are these realised as elements?
... In order to address these questions, the research team
looked at utilizing systems development as an exploratory
research approach. (p.
317)
Attention is drawn to the expression ‘exploratory research
approach’ here. When research is being undertaken to elucidate
ill-defined issues, exploration of them is what, in fact,
is required.
In some research projects, design-research is undertaken
in formal, tight, iterative phases. Something is designed,
built, tested, redesigned, in a number of phases. At
other times, however, design research is undertaken in less
linear cycles, with these processes often happening simultaneously.
So it is in this case. The strategies adopted in the research are those that
are expected to best elucidate what is required of the metadata.
Although these are exercised simultaneously in most cases,
they have been reordered for reporting purposes into what is now more or less
a sequential set of activities.
Research activities
The research provides the first significant description
of issues relevant to AccessForAll metadata and how it can
be used. It justifies the development of such an approach
to accessibility, and shows how the actual metadata schemas
can be developed. This involves a wide range of research
activities, as shown below.
To investigate how effective accessibility
efforts were in a typical organisation, the author was involved
in the auditing of
a major university Web site (Nevile,
2004). The process was significantly simplified by the
combined use of several automation tools. The audit produced
descriptions (metadata) of the accessibility characteristics
of the 48,084 pages reviewed.
To facilitate the use of the WCAG specifications by content
developers, the Accessible Content Development Web site (Appendix
8)
was built. The aim was to provide a fast
look-up site organised by topic and focus, rather than the
lengthy, integrated approaches required at the time by anyone
using the W3C Web Content Accessibility Guidelines [WCAG-1].
As a result of doing this work, the author gained a more
structured view of the difficulties being tackled by developers
in practice. This complemented previous work in which the
author had, on many occasions, been consulted with respect
to building accessible sites or to ascertain the accessibility
or otherwise of sites, and many times commissioned to repair
the sites.
To develop an automatic service for conversion of MathML encoded
mathematics into Braille, a major Braille project was undertaken at La Trobe University with support from Melbourne University and the Telematics Trust Fund [Telematics Trust].
The first task was to understand the problems, then to see
what partial solutions were available, and then to develop
a prototype service to convert mathematics texts to Braille.
In this case, there was no need to survey anyone to determine
the size of the problem or the satisfaction available from
existing solutions - the picture was patently bleak for the
few Braille users interested in mathematics and, in particular,
the text was required by a Melbourne University student for
his study program. Ultimately, the research was grounded in
computer science, where it is common to have a prototype as
the outcome with an accompanying document that explains the
theoretical aspects and implications of the prototype. In this
case, the prototype encoding work was undertaken by a student
who was supervised by the author, who herself managed or personally
did much of the other work in the project (Munro,
2007; Nevile et al, 2005).
To gain an insight into formal empirical research documenting
specific problems with the W3C WAI Web Content Accessibility
guidelines, the author studied the UK’s Disabilities Rights
Commission’s review of 1000 Web sites. This was the first major
review of Web sites that evaluated the WCAG’s effectiveness.
Many of the findings have more recently been substantiated
in other work (see Chapter 4)
and they have been anecdotally reported by the author and others
for many years.
The author wanted to know that AccessForAll
metadata could be applied automatically
to resources of interest for their accessibility, using their
existing metadata descriptions. So information
from major suppliers of accessible resources was gathered to
verify the existence of such resources and their metadata
(Chapter
7).
To learn how AccessForAll ideas might operate in a distributed
environment, the author studied the Functional Requirements
for Bibliographic Records (FRBR)
and associated work and tried to determine how resources should
be described so that other resources with the same content
but represented in different modes or with other variations
might be discoverable. This work was undertaken at the Knowledge Communities Research Center [KCRC] in Japan with
colleagues who, at the time, were trying to learn from FRBR
and the OpenURI work. The author is more inclined to think
that a new approach to resource description to be known as
GLIMIRs may, in fact, prove more useful in this context (see
above).
To make sure AccessForAll metadata would be interoperable
with other metadata systems, and DC metadata in particular,
the author studied the emerging DC abstract data model. To
this end, the author worked with data models expressed in
formal notation (Unified Modeling Language [UML]).
Through this work, the author discovered the ambiguity of the
DC Abstract Model as first expressed and became involved in
work to clarify that model (Pulis &
Nevile, 2006). Eventually, the DC model was expressed
in UML and the model proposed for the DC implementation AccessForAll
metadata was matched to that model. There is a strong feeling
emerging that unless data models are matched, the metadata
cannot interoperate without a significant loss of data (Weibel,
2008b).
There are many major players in the field of accessibility.
These stakeholders had to be won over. There is really
no other way that technologies such as metadata schemas proliferate
on the Web. Without the engagement of major players, the technologies
are not useful, as explained above. 'Winning over' bodies that
use technologies usually means providing a strong technical solution
as well as compelling reasons (in implementers' eyes) for adoption
of those technologies. In the case of accessibility metadata,
the technical difficulties are substantial. As explained in
the section on metadata, there are many kinds of metadata and
yet they share a goal of interoperability - essential if the
adoption is to scale and essential if it is to be across-institutions,
sectors, or otherwise working beyond the confines of a single
environment. The problems related to interoperability are considered
later (Chapter
11)
but they are not the only ones: metadata is frequently required
to work well both locally and globally, meaning that it has
to be useful in the local context and work across contexts.
This tension between local and global is at the heart of the
technical challenges for adoption when diverse stakeholders
are involved and so competes with the political and affective challenges.
At the time the AccessForAll work was being undertaken, a
major review of accessibility was being undertaken by the ISO/IEC
JTC1. A Special Working Group [SWG-A]
was formed to do three things: to determine the needs of people
with disabilities with respect to digital resources, to audit
existing laws, regulations and standards that affect these,
and to identify the gaps. Concerned that this was merely a
commercially-motivated use of a standards community
with an agenda to minimise the need for accessibility standards
compliance, the author asked to know the affiliations of
the people represented in the Working Group. Most were employed
by one single, major international technology company
although they were presented as national body representatives.
There were very few representatives of disability or other
interest groups. In fact, when the author
asked if the people present
could identify their affiliations, it took an hour of debate
before this was allowed. Not only was the author uneasy about
the disproportionate commercial representation, but it emerged
that the agenda was constantly under pressure to do more than
the stated research work, and to try to influence the development
of new regulations that were seen to threaten the major technology
companies. Although heavy resistance to the 'commercial' interests
was provided by a minority, and in the end the work was limited
in scope to the original proposals, it showed just how much
effort is available from commercial interests when they want
to protect their established practices. Given that many of
the companies represented in the SWG-A are also participants
in consortia such as W3C, IMS GLC, it is indicative of
what was potentially constraining of the AfA work of the AfA
team. More recently, this trend has again been demonstrated
by the efforts of Microsoft to have their proprietary document
standard OOXML approved as an international standard. In that
case, there have been legal cases about the problems of representation
and decision-making (McDougall,
2008).
Finally, simultaneously with the research, the ISO/IEC JTC1 SC 36 WG 4 has been developing a standard for metadata for learning resources [ISO/IEC N:19788]. The author has been active in this work as it will result in a standard to be followed that should avoid the problems revealed by the research in the case of the AccessForAll metadata.
In design experiments, or research using design experiments
(design research), it is a feature
of the process that the goals and aspirations of those involved
are considered and catered for. In fact, as the work evolves,
the goals of the various parties are constantly revisited
as the circumstances change and the
research informs the design of the experiments.
The current research
is not about a researcher testing a hypothesis on a randomly
selected group of subjects; the stakeholders and the designers
interact regularly and advantage is taken of this to guide
the design. The practical aspects are constantly revised according
to newly emerging theoretical principles and the new practical
aspects lead to revised theories. The goals do not change but
the ways of achieving them are not held immutable.
In this work, considerable interaction occurs
between the author as researcher and the author and
colleagues and other stakeholders in the design process.
This is especially exemplified in the various voting procedures
that move the work through the relevant standards bodies.
These formal processes take place at regular intervals and
demand scrutiny of the work by a range of people followed by
votes of support for continued work. Challenges to the work,
when they occur, generally promote the work in ways that lead
to revisiting of decisions and revising of the theoretical
position being relied upon at the time. Such challenges also
provide insight for
the researcher into the problems and solutions being proposed.
In particular, the author sits between two major metadata
camps. Those involved in the IMS GLC have experience mainly
with relational databases and LOM metadata, which is very 'hierarchical'.
On the other hand, the DC community is biased towards 'flat'
metadata. The DC view inevitably influenced the author,
given her role as Chair of the DC Accessibility Working Group
(later the DC Accessibility Community) and membership of the
Advisory Board of DCMI. The IMS
GLC's interests are for an outcome that will suit them
but, as the author saw it, could risk even further fragmentation
of the total set of resources available to education, and so
not serve the author's real goal which is to increase the
accessibility of the Web (of resources).
During the research period, DCMI itself has been wrestling with the
problem of interoperability of the LOM and DC educational community's
metadata, a difficulty that has been present since the first
educational application profile was proposed by the author nearly a decade
ago (for Victorian Education Channel). The interoperability is necessary given that, for example,
government resources might be used in educational settings
and if their metadata can not be cross-walked (see Chapter
6) from one scheme to the other, the descriptions of the
government resources will not be useful to educationalists,
which seems ridiculous. One way to ease the problem might have
been to develop a standard that suits both metadata
systems and that might have been possible (see Chapter
11),
but there was insufficient technical expertise available to
achieve that goal, so the best that could be done in the circumstances
became the modified goal. This has been achieved and it is possible
to cross-walk between the various metadata standards so that
it does not matter so much which is used, because the data
of the metadata descriptions can be shared without loss.
The design work reported has been progressively adopted
and has now become part of the Australian standard for all
public resources on the Web (as the
AGLS Metadata Standard)
and by virtue of being an ISO standard [ISO/IEC JTC1 N:24751], an educational standard
for Australia. This can be taken as indicative of it having
proven satisfactory to a considerable number of people. Only
actual implementation and use will prove it to have been truly
successful because it will need to be proliferated to the extent
that it becomes useful. Implementations are discussed further
in Chapter
11.
Chapter Summary
In this chapter, attention has been paid to the immediate need for working definitions of the terms accessibility, metadata, Web 2.0, and others, and the scope and type of the research. These will all be further elaborated in the following chapters.
The research establishes that, given an understanding
of the field of accessibility, the context for it, and frustration
with the lack of success and the results of recent research,
it is evident that for all the good intentions, there has been
poor implementation of accessibility techniques. Universal
design is not a sufficient strategy even if it is applied,
and a narrow focus on specifications for authoring of Web content
alone will not produce the desired results. This means there
is a need for a new approach. By using a range of existing
and emerging standards and introducing metadata to describe
user needs and preferences, it is possible for them to be matched by
resource characteristics, also described in metadata. By adding
this possibility, without compromising interoperability of
metadata or stakeholder interests, and by attracting implementation,
individual access needs and preferences should be able to be
satisfied. This AccessForAll approach places emphasis on the
accessibility of the Web for individuals, and involves many
standards working together. It does not depend upon universally accessible
resources but includes them. It will be elaborated in the next chapter.
Next -->
 This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile
This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 2.5 Australia License.
© 2008 Liddy Nevile